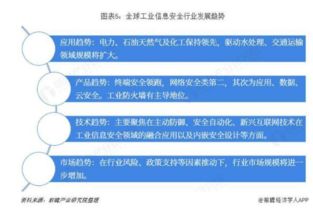
数据饥荒 互联网信息枯竭或成AI技术发展的新瓶颈
人工智能技术迎来了爆发式的增长,从语言模型到图像生成,从自动驾驶到智能医疗,AI正以前所未有的速度渗透到各个领域。在这片繁荣景象的背后,一个潜在的危机正在悄然浮现:互联网上的高质量信息似乎正在变得“不够用”了。数据短缺正逐渐成为制约AI技术进步的新难题,这一问题在互联网信息技术开发领域尤为突出。
数据需求与供给的失衡
当前主流的AI模型,尤其是大语言模型和生成式AI,其训练往往依赖于海量的互联网数据。以GPT-4等顶尖模型为例,其训练数据量已高达数万亿 tokens,几乎涵盖了整个可公开获取的互联网文本。互联网信息的增长并非无限。高质量、结构化、标注清晰的文本、图像、视频数据增长速度,已经难以匹配AI模型对数据日益增长的“胃口”。
一方面,AI模型的参数量和数据需求呈指数级增长,每一次性能的飞跃都伴随着对训练数据规模的更高要求。另一方面,互联网上易于获取的“低垂果实”——如维基百科、主流新闻网站、公开书籍、学术论文等高质量语料——已被反复挖掘。新增的高质量信息的产生速度远跟不上AI消耗的速度,导致数据供需出现结构性失衡。
数据质量的隐忧与“数据废气”的循环
即便数据量的问题可以通过不断爬取新网页来暂时缓解,但数据的质量正成为更严峻的挑战。互联网上充斥着大量重复、低质、带有偏见甚至虚假的信息。AI模型如果过度依赖这些“数据废气”(data exhaust)进行训练,不仅会导致模型性能陷入瓶颈,还可能放大社会偏见,产生事实性错误或有害输出,即所谓的“垃圾进,垃圾出”(Garbage In, Garbage Out)。
更令人担忧的是,随着AI生成内容(AIGC)的大规模普及,互联网本身正在被AI产生的内容所“污染”。爬虫抓取到的信息中,将混杂越来越多由其他AI模型生成的内容。如果下一代AI再用这些“合成数据”进行训练,可能导致模型陷入自我循环,性能退化,甚至出现“模型崩溃”(Model Collapse)现象,即输出变得同质化、失真或荒谬。
对互联网信息技术开发的挑战与机遇
这一数据困境对互联网信息技术开发提出了全新的挑战:
- 数据获取方式的革新:开发者不能再单纯依赖公开爬取。未来可能需要转向更多元的数据获取策略,包括:
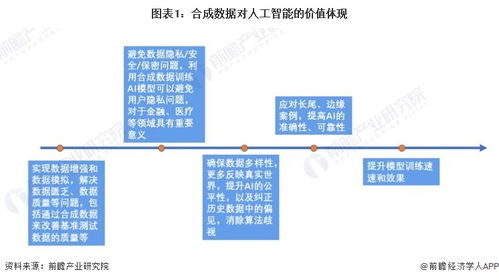
- 合成数据生成:利用AI本身创造高质量、多样化的训练数据,但这需要解决真实性、多样性和偏见控制等核心问题。
- 小数据与高效学习:研究如何用更少的数据训练出强大的模型,例如通过更先进的算法(如小样本学习、元学习)、更好的模型架构(如混合专家模型MoE)或更精细的提示工程。
- 隐私计算与数据联邦:在保护用户隐私的前提下,合法合规地利用分散在各机构、企业中的私有数据,打破“数据孤岛”。
- 数据处理技术的升级:对数据的清洗、去重、标注和评估变得比以往任何时候都更重要。开发更智能的数据治理工具和评估基准,确保输入模型的数据是“高营养”的,将成为技术开发的关键环节。
- 商业模式与生态的重构:高质量数据可能成为比算法更稀缺的战略资源。这可能会催生专业的数据市场、数据合作社等新业态,知识产权、数据所有权和收益分配的规则也需要重新定义。
迈向“质”胜于“量”的新时代
互联网信息“不够用”的警报,标志着AI发展正从依赖“数据规模红利”的粗放阶段,转向追求“数据质量与算法效率”的精细化阶段。这虽然带来了阵痛,但也迫使整个行业进行深刻反思与技术转向。未来的AI技术进步,将不再仅仅比拼谁能获取更多的数据,而是比拼谁能更聪明、更高效、更负责任地利用数据。对于互联网信息技术开发者而言,谁能率先在数据获取、处理和使用的全链条上实现创新,谁就更有机会在AI发展的下一波浪潮中占据先机。克服数据短缺的难题,或许正是推动AI技术走向更稳健、更可信、更可持续发展道路的关键契机。
如若转载,请注明出处:http://www.84000data.com/product/69.html
更新时间:2026-06-19 16:28:03